using git rebase to remove duplicate cherry-picked commits
Git cherry-pick is a great tool, it allows you to select individual commits from a branch and merge them into another. However, if the branch that you cherry-picked from is eventually merged to the same branch that the individual commits landed, you end up with duplicate commits.
To demonstrate this behaviour, we assume that we are working on a project
and at some point, we branched off to a dev branch to work on some exciting
new feature. As we are working we find some other important issues, or maybe
some minor issues that are not relevant to the new feature and decide to fix
them too. Now, there are two approaches we can take in such situation. The
first is to commit in our current branch and then use git cherry-pick to
introduce these changes to the master (or some other) branch. The second
approach is to stash any unsaved changes, create another branch
and commit these changes there. I personally prefer the second approach
as it makes your life way easier if your are contributing on a
project and need to make a pull request on Github or create a patch.
For our example, we will take the first approach and commit anyway.
So, after some work on the dev branch, the tree will look like this:
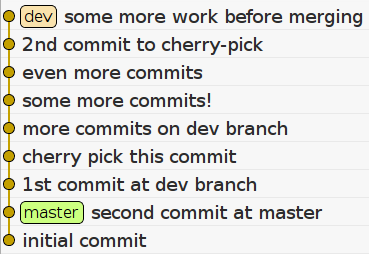
I have used silly commit messages like “cherry-pick this commit” to indicate which commits we will cherry-pick into the master branch. Let’s do that now:
$ git checkout master
$ git cherry-pick e22c44f
$ git cherry-pick 1a2929aIf we use git log on master, we will notice that we have our new
commits, but with different SHA-1 hashes. This is happening because when
we cherry-pick commits, git creates new
commits on the master branch which introduce
the changes of these commits. At this point, the state of
the repo is the following:
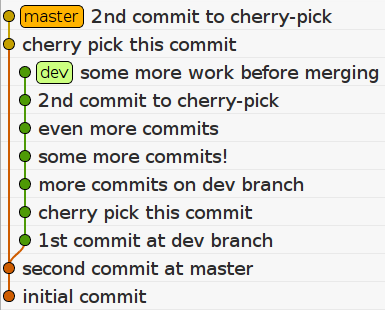
At some point, we are happy with the work on the dev branch, and
decide to merge the dev into master. However the master
branch has changes since the time we initially branched to work on our
features. This means that we cannot use a fast-forward merge.
If we switch to master branch and run git merge dev then a new
commit will be introduced. This is the standard behaviour of git when
doing no-fast-forward merges. Sometimes this may be desirable, but
some other times we prefer a linear history. This will be the repository
state after a merge:
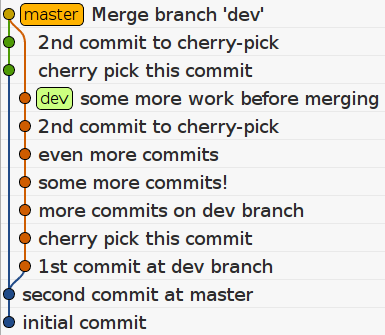
And a git log --oneline will look like this:
b05bcc3 Merge branch 'dev'
b47ebea 2nd commit to cherry-pick
9d190e9 cherry pick this commit
8c0a87e some more work before merging
d1c9568 2nd commit to cherry-pick
9d4575e even more commits
790c30a some more commits!
ac60758 more commits on dev branch
03725e0 cherry pick this commit
2e106d4 1st commit at dev branch
ee38cc6 second commit at master
444357a initial commitNotice that except from the (ugly) new commit on top, we also ended up
with duplicate commits for each cherry-picked commit. Also, if you care
enough to use the git show command you will notice
that these duplicate commits contain the same changes.
This is where the rebase command comes into play. Rebase can be used
to rewrite the git history. It allows us to extract the changes of a
commit(s) and re-apply it ontop of a branch.
We will use it to introduce the new commits of the master branch to our dev branch and then replay all the work of the dev branch on top of these commits. In our use case, the “new” commits of the master branch are the cherry-picked changes. When rebase will start to re-apply our work, it is smart enough to not apply the same changes the second time, and thus removing the duplicate commits. Running:
git checkout dev
git rebase masterwill bring our repository in the following state:
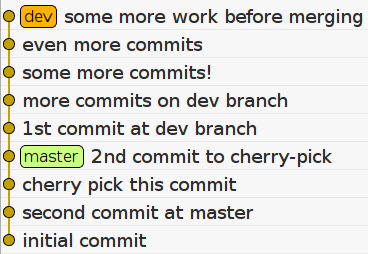
As you can see, the cherry-picked commits look like they never existed on the dev branch. Also, now we can use a fast-forward merge:
git checkout master
git merge --ff devYou can find more information about rebasing and cherry-pick at the git-book and the relevant man pages.